ENIGMA: как прочитать мысли за 15 минут с дешёвым датчиком на голове
Авторы: Reese Kneeland, Wangshu Jiang, Ugo Bruzadin Nunes, Paul Steven Scotti, Arnaud Delorme, Jonathan Xu

Зачем это важно
Представьте: вы надеваете компактную гарнитуру с электродами, смотрите на экран 15 минут — и после этого компьютер может буквально видеть то, что видите вы. Не размытые пятна, а узнаваемые изображения: апельсины, овец, мебель, лица.
Звучит как научная фантастика, но именно это продемонстрировала команда исследователей в работе ENIGMA. И самое интересное — для этого не нужен МРТ-сканер за десятки тысяч долларов. Достаточно ЭЭГ-гарнитуры, которую можно купить онлайн.
Основная идея
ENIGMA — это модель, которая восстанавливает изображения из электрической активности мозга, записанной через ЭЭГ (электроэнцефалографию).
ЭЭГ (электроэнцефалография) — метод записи электрической активности мозга через электроды на поверхности головы. В отличие от МРТ, не требует громоздкого оборудования и может использоваться в повседневных условиях.
Три прорыва отличают ENIGMA от всех предыдущих подходов:
-
15 минут вместо часов. Предыдущие системы требовали часы данных для каждого нового пользователя. ENIGMA достигает лучших результатов после 15-минутной калибровки.
-
Менее 1% параметров. Модель в 165 раз компактнее конкурентов при обслуживании 30 пользователей одновременно — это делает реальной работу на обычных устройствах.
-
Работает с дешёвыми датчиками. Конкуренты ломаются на потребительских ЭЭГ-гарнитурах ($2200). ENIGMA сохраняет работоспособность.
Как это работает
Рис. 1: Архитектура ENIGMA — сигнал проходит через общий backbone, индивидуальный слой выравнивания, MLP-проектор и генератор изображений.
Архитектура ENIGMA состоит из четырёх последовательных блоков:
1. Пространственно-временной backbone. Сырой сигнал ЭЭГ (каналы x временные точки) обрабатывается как двумерная «картинка». Временные свёртки улавливают паттерны во времени, пространственные — связи между электродами. На выходе — компактный вектор из 184 чисел.
Backbone — основная «хребтовая» часть нейросети, которая извлекает ключевые признаки из входных данных. Все остальные компоненты строятся поверх неё.
2. Индивидуальные слои выравнивания. Мозг каждого человека генерирует сигналы немного по-разному. Вместо отдельной модели для каждого, ENIGMA добавляет крошечный персональный слой (184×184 весов) — это и есть секрет экономии параметров.
3. MLP-проектор. Преобразует 184-мерный вектор мозговой активности в 1024-мерное пространство CLIP — универсального представления визуальной информации.
CLIP — модель от OpenAI, которая «понимает» связь между изображениями и текстом. Работает как общий язык между зрением и мышлением для ИИ.
4. Генератор изображений. Stable Diffusion XL Turbo превращает вектор CLIP в финальное изображение всего за 4 шага диффузии.
Ключевая находка: авторы отказались от нормализации целевых CLIP-векторов в функции потерь (в отличие от конкурентов), что сохраняет геометрию пространства представлений и устраняет необходимость в отдельном «диффузионном приоре».
Результаты
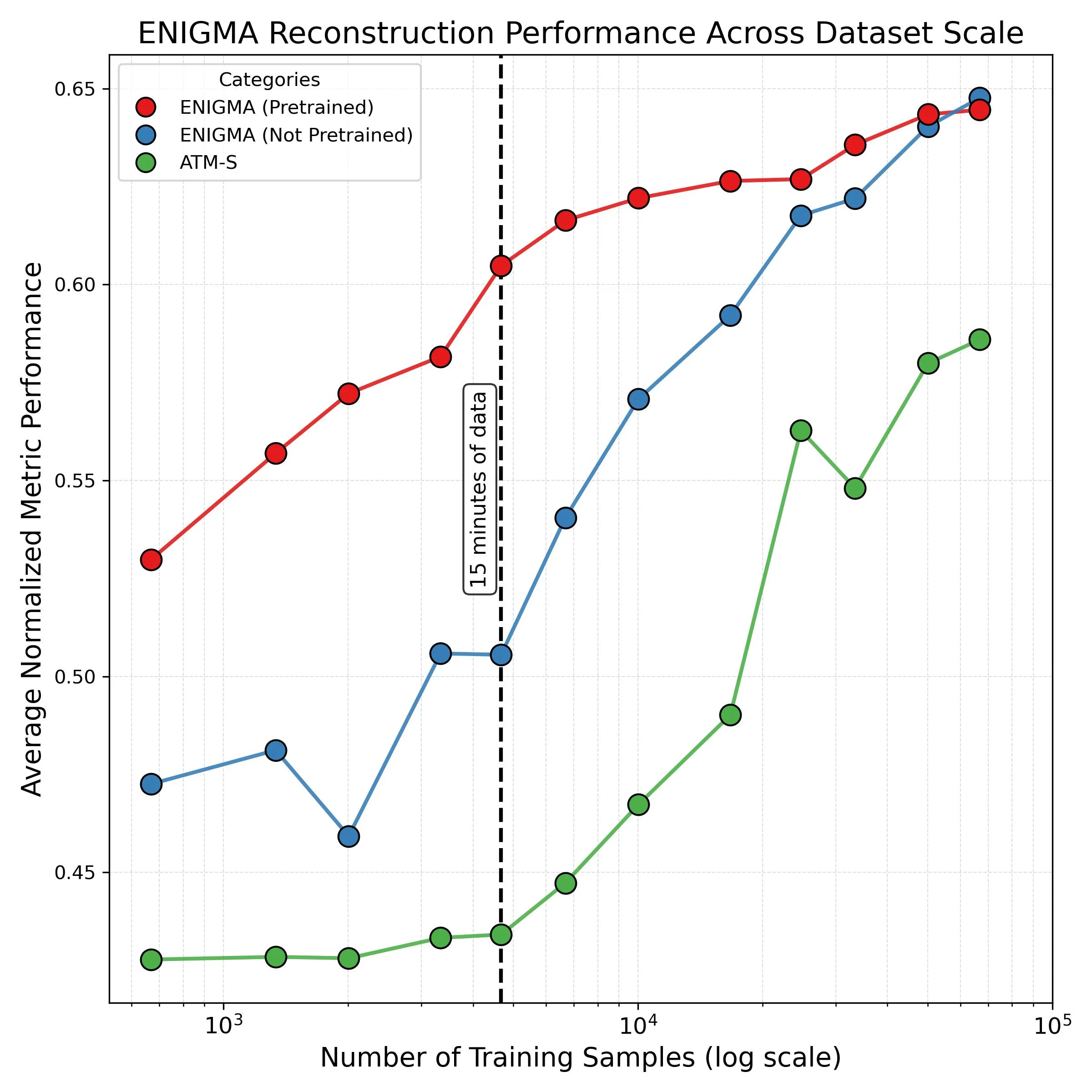
Рис. 2: После 15 минут калибровки предобученная ENIGMA (красная линия) уже превосходит полностью обученный конкурент ATM-S (зелёная линия).
Модель протестирована на двух наборах данных:
- THINGS-EEG2 — исследовательская аппаратура за ~$60 000, 64 канала, 1000 Гц
- AllJoined-1.6M — потребительская гарнитура за ~$2 200, 32 канала, 250 Гц
| Метрика | ENIGMA | ATM-S (конкурент) | Perceptogram |
|---|---|---|---|
| Точность CLIP | 80,3% | 55,0% | — |
| Распознавание людьми | 86,0% | 56,8% | — |
| Параметры (30 чел.) | 2.4M | 384M | 4 700M |
На потребительском оборудовании (AllJoined-1.6M) ENIGMA набирает 70,7% точности распознавания людьми, тогда как ATM-S — всего 52,2%.
Человеческая оценка. 545 добровольцев участвовали в слепом тестировании: им показывали оригинал и две реконструкции, и просили выбрать более похожую. ENIGMA побеждала во всех условиях.
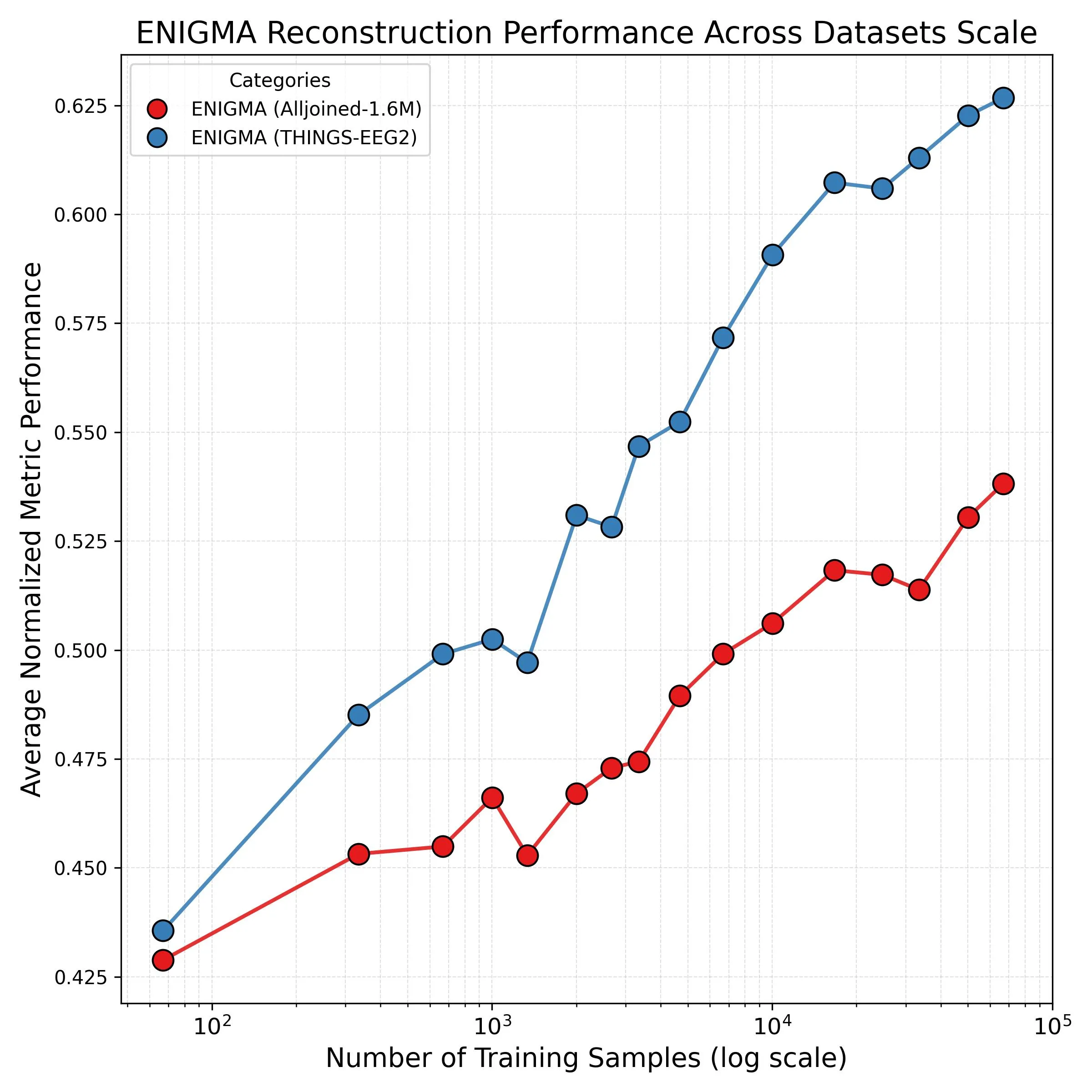
Рис. 3: Логарифмическая зависимость качества от объёма данных. Исследовательское оборудование (синий) масштабируется лучше потребительского (оранжевый).
Критический взгляд
Дисклеймер: Это автоматический анализ на основе открытых данных, а не экспертная рецензия. Статья является препринтом и не прошла формальное рецензирование.
Сильные стороны:
- Впервые продемонстрирована работа на потребительском ЭЭГ-оборудовании с сохранением достойного качества
- Радикальное сокращение параметров (в 165 раз) делает реальным развёртывание на обычных устройствах
- Первое исследование с поведенческой оценкой (545 человек) — а не только автоматическими метриками
- Воспроизводимость: модель работает на GPU с 8 ГБ VRAM, код обещан к публикации
Ограничения:
- Масштабирование по числу пользователей не даёт прироста качества — добавление новых субъектов не улучшает «потолок» модели
- Тестирование проведено только в узком сценарии реконструкции изображений — как модель покажет себя в других BCI-задачах, неизвестно
- Качество сильно зависит от оборудования: разрыв между исследовательским ($60K) и потребительским ($2.2K) датчиком заметен
Открытые вопросы:
- Может ли модель декодировать мысленные образы (а не только то, что человек видит прямо сейчас)?
- Каковы этические рамки применения такой технологии? Авторы сами призывают к созданию этического фреймворка — но пока его нет
Выводы
ENIGMA — это шаг от лабораторных демонстраций к реальным интерфейсам «мозг-компьютер». Когда для декодирования визуального опыта достаточно 15 минут калибровки и гарнитуры за $2200, технология перестаёт быть игрушкой для нейроучёных.
Но вместе с возможностями приходят и риски. Авторы честно признают: способность читать визуальный опыт из мозговой активности требует жёстких этических рамок — для защиты приватности, прозрачности и ответственного использования. Пока таких рамок нет, каждый шаг вперёд в «чтении мыслей» — это одновременно и надежда, и предупреждение.