ENIGMA: How to Read Minds in 15 Minutes with a $2,200 Headset
Authors: Reese Kneeland, Wangshu Jiang, Ugo Bruzadin Nunes, Paul Steven Scotti, Arnaud Delorme, Jonathan Xu

Why It Matters
Imagine putting on a compact headset with electrodes, looking at a screen for 15 minutes — and after that, a computer can literally see what you see. Not blurry blobs, but recognizable images: oranges, sheep, furniture, faces.
Sounds like science fiction, but that’s exactly what ENIGMA demonstrates. And the most exciting part — it doesn’t require an MRI scanner costing tens of thousands of dollars. A consumer EEG headset you can buy online is enough.
The Core Idea
ENIGMA is a model that reconstructs images from electrical brain activity recorded through EEG (electroencephalography).
EEG (electroencephalography) — a method of recording electrical brain activity through electrodes placed on the scalp. Unlike MRI, it doesn’t require bulky equipment and can be used in everyday settings.
Three breakthroughs set ENIGMA apart from all previous approaches:
-
15 minutes instead of hours. Previous systems required hours of data for each new user. ENIGMA achieves superior results after just 15 minutes of calibration.
-
Less than 1% of parameters. The model is 165 times more compact than competitors when serving 30 users simultaneously — making real deployment on ordinary devices feasible.
-
Works with affordable sensors. Competitors break down on consumer EEG headsets ($2,200). ENIGMA maintains performance.
How It Works
Fig. 1: ENIGMA architecture — the signal passes through a shared backbone, individual alignment layer, MLP projector, and image generator.
ENIGMA’s architecture consists of four sequential blocks:
1. Spatio-temporal backbone. The raw EEG signal (channels × time points) is processed as a 2D «image.» Temporal convolutions capture patterns over time, spatial ones capture inter-electrode relationships. Output: a compact 184-dimensional vector.
Backbone — the core component of a neural network that extracts key features from input data. All other components are built on top of it.
2. Subject-wise alignment layers. Each person’s brain generates slightly different signals. Instead of a separate model for each user, ENIGMA adds a tiny personal layer (184×184 weights) — this is the secret to parameter efficiency.
3. MLP projector. Transforms the 184-dimensional brain activity vector into CLIP’s 1024-dimensional space — a universal representation of visual information.
CLIP — a model by OpenAI that «understands» the relationship between images and text. It serves as a universal language between vision and reasoning for AI systems.
4. Image generator. Stable Diffusion XL Turbo converts the CLIP vector into a final image in just 4 diffusion steps.
Key insight: the authors dropped normalization of CLIP targets in the loss function (unlike competitors), preserving the embedding space geometry and eliminating the need for a separate «diffusion prior» training stage.
Results
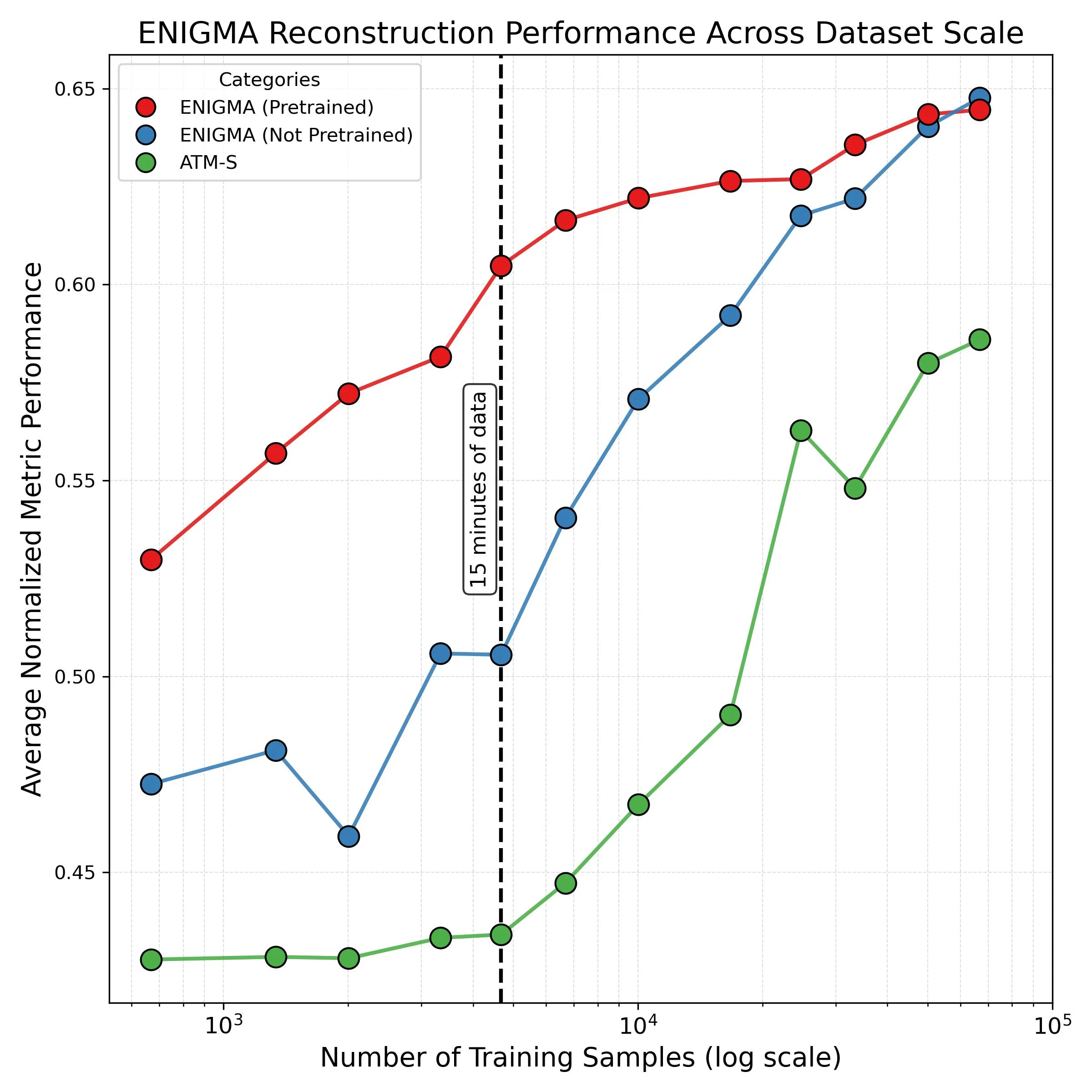
Fig. 2: After 15 minutes of calibration, pretrained ENIGMA (red line) already surpasses fully-trained competitor ATM-S (green line).
The model was tested on two datasets:
- THINGS-EEG2 — research-grade equipment (~$60,000), 64 channels, 1000 Hz
- AllJoined-1.6M — consumer headset (~$2,200), 32 channels, 250 Hz
| Metric | ENIGMA | ATM-S (competitor) | Perceptogram |
|---|---|---|---|
| CLIP accuracy | 80,3% | 55,0% | — |
| Human identification | 86,0% | 56,8% | — |
| Parameters (30 users) | 2.4M | 384M | 4,700M |
On consumer equipment (AllJoined-1.6M), ENIGMA achieves 70,7% human identification accuracy, while ATM-S scores only 52,2%.
Human evaluation. 545 volunteers participated in a blind test: they were shown an original image and two reconstructions, and asked to choose the more similar one. ENIGMA won across all conditions.
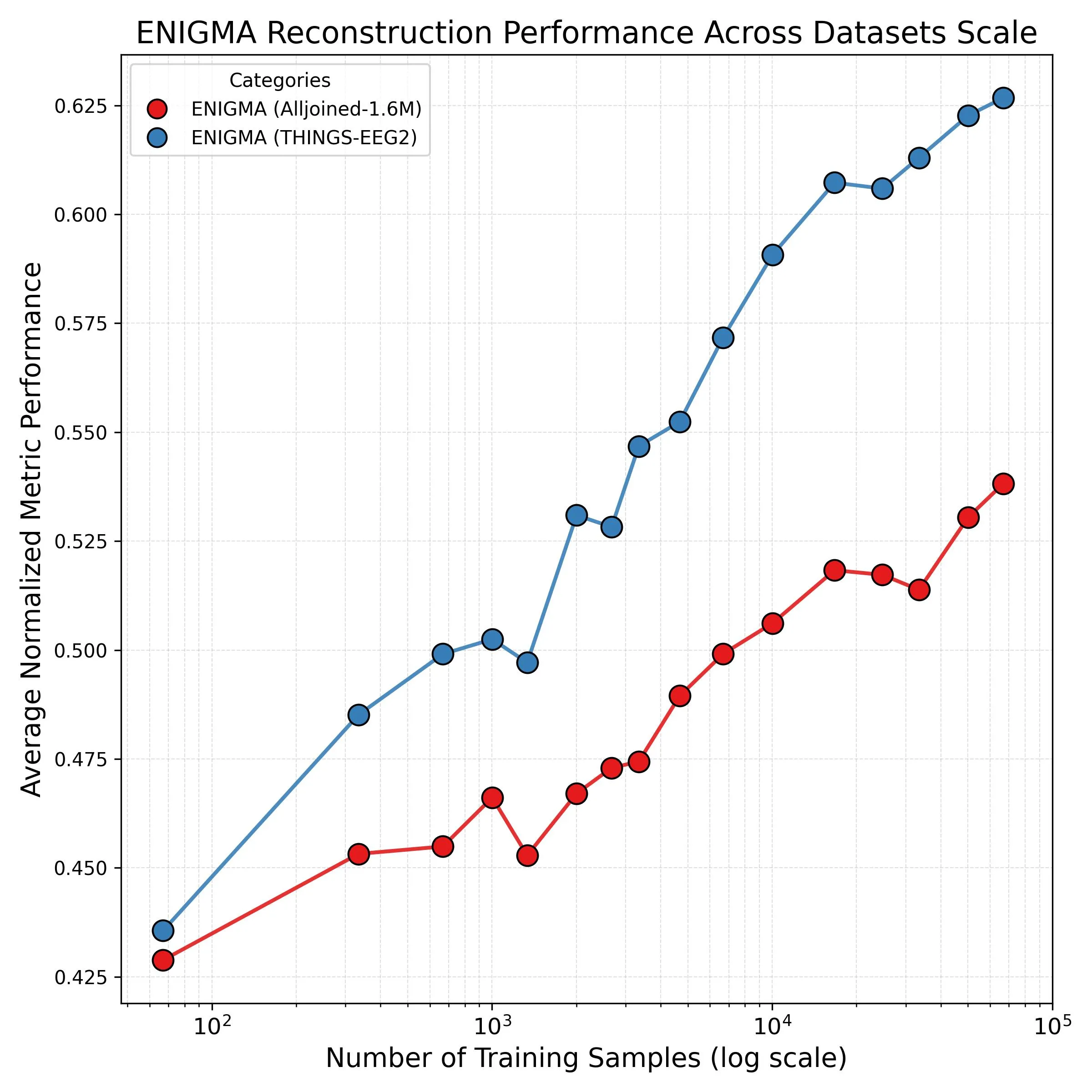
Fig. 3: Log-linear relationship between data volume and quality. Research-grade equipment (blue) scales better than consumer-grade (orange).
Critical Analysis
Disclaimer: This is an automated analysis based on publicly available data, not an expert peer review. The paper is a preprint and has not undergone formal peer review.
Strengths:
- First demonstration of consumer-grade EEG decoding with competitive quality
- Radical parameter reduction (165x) makes real-world deployment feasible
- First study with behavioral evaluation (545 humans) — not just automated metrics
- Reproducibility: runs on GPUs with 8 GB VRAM, code publication promised
Limitations:
- Multi-subject scaling doesn’t improve quality ceiling — adding more users doesn’t raise the performance cap
- Testing only in a narrow image reconstruction scenario — how the model performs on other BCI tasks is unknown
- Quality still depends heavily on hardware: the gap between research ($60K) and consumer ($2.2K) equipment is significant
Open Questions:
- Can the model decode mental imagery (not just what a person is currently seeing)?
- What are the ethical boundaries for such technology? The authors themselves call for an ethical framework — but none exists yet
Conclusions
ENIGMA is a step from laboratory demonstrations toward real brain-computer interfaces. When decoding visual experience requires only 15 minutes of calibration and a $2,200 headset, the technology stops being a toy for neuroscientists.
But with capabilities come risks. The authors honestly acknowledge: the ability to read visual experience from brain activity demands strict ethical frameworks — for privacy protection, transparency, and responsible deployment. Until such frameworks exist, every step forward in «mind reading» is simultaneously a promise and a warning.